
はじめに
こんにちは。データ分析チーム・入社1年目のルーキー、小池です。
データ分析チームでは、画像処理・自然言語処理など様々な分野に取り組んでおり、機械学習や多変量解析を用いたデータの分析を行っています。
そんな中で私は機械学習・Deep Learningによる画像処理系の分析を行っています。
本記事では、私達の取り組みの一部をご紹介すると同時に、画像分析の面白さを体感していただければと思います。
今回のテーマ
今回のテーマは、AI(機械学習・Deep Learning等)を用いて、 大量にある顔画像の中から同一人物をクラスタリングし、頻出する顔画像の抽出 を行いたいと思います。
簡単に言うと、 たくさんある画像から同じ人を見つけること を機械(AI)にやらせるということです。
目的
「たくさんある画像から同じ人を見るけること」ができれば、以下1~3の流れで、店舗に来るお客さんが常連さんか否かが判定ができるのではないかと考えています。
- 店舗にカメラを設置し、1ヶ月程来店したお客さんの顔画像を収集
- 収集した顔画像に対して同じ人の画像があるかどうかを見つける
- 同じ人の画像が見つからなかったら新規のお客さん、見つかったら常連さんと判定
画像により新規のお客さん・常連さんの判定ができたとすると、マーケティング分析やサービスの向上への活用が期待できそうです。
- よく来店するお客さんと初めて来店されるお客さんの購買行動を比較し、マーケティング戦略に活かす
- 今回のテーマで抽出した顔画像を元にDeep Learningのモデルを作り、その場で常連さんか否かを判断し、現場のサービス向上につなげる
前者の顧客分析は、従来はポイントカードを発行しPOSレジをお店に導入しないとなかなか実現できなかったのではないかと思います。また、後者のサービス向上についても、現時点では店員さんの記憶や経験だけに頼っている現場が多いのが実情では無いでしょうか?
こういったことが、今回のような画像処理技術とカメラ1つで実現できそうだということで、非常にワクワクしています。
方針
「たくさんある画像から同じ人を見るけること」実現に向け、下記1~3で進めていきます。
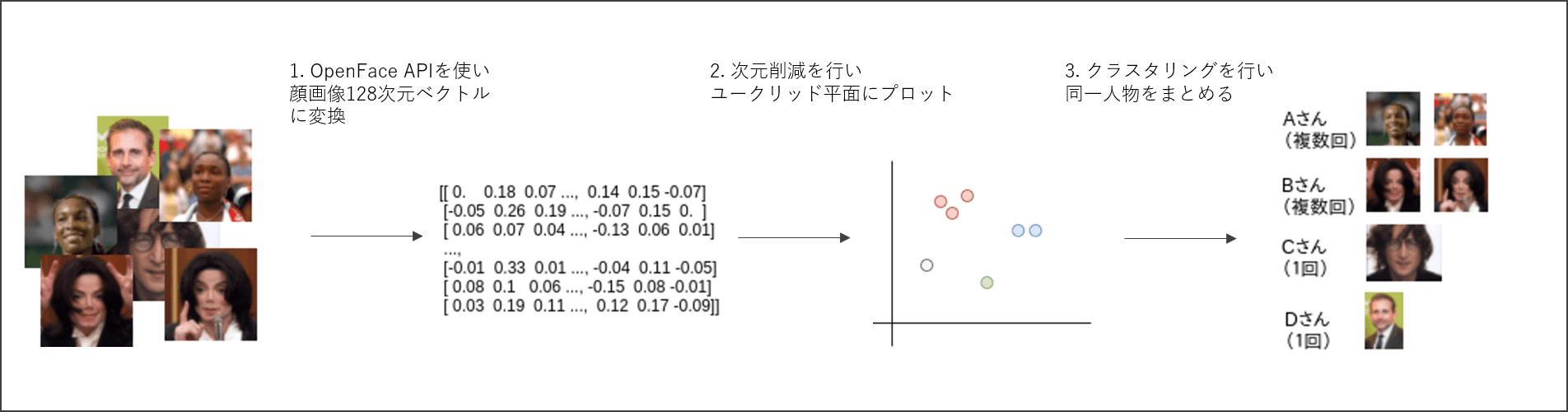
- OpenFace API(Deep Learning)を利用し、顔画像を抽出・表現獲得を行う
- 結果は128次元ベクトルに変換される
- 顔画像に対して次元削減を行い、ユークリッド平面にプロットし可視化
- 表現獲得した画像をクラスタリングして同一人物をまとめる
開発環境の構築
画像解析と相性が良いDockerを使おう
Dockerとは、仮想化のためのオープンソースで、1つのOS上に複数の仮想環境を簡単に用意できます。
また、Docker HubというDockerで構築された環境をシェアする仕組みがあり、ありがたいことにエンジニアが数日間かけて構築したような複雑な環境も数多く共有されています。
今回のような画像分析の開発構築は、一昔前までちょっとした環境差異でインストールができなかったりと非常に苦労を伴ったそうですが、今ならDockerを利用することでコマンド一つで準備できます。
また、Deep LearningではGPGPUを用いていますが、nvidia-dockerがあればGPGPU環境も整います。
みなさんもぜひ導入してみて下さい。
今回はGPU環境を利用しないので、Dockerのみ入っていればOKです。
開発環境
- Ubuntu 16.04 LTS
- 私はUbuntuを開発で利用していますが、Dockerが入っていれば問題ないと思います
- Docker 1.13.0 (Client,Server)
環境構築手順
Dockerは導入されている前提で進めます。
1. コンテナを取得 & 実行
bamosさんの作成したopenface(後に記述)の環境を使わせていただきます。
python2,3、numpy、OpenCV、scikit-learn、Dlibが入っているのですぐに画像解析が始めることができます。
$ docker pull bamos/openface
$ docker run -v /home/{your dir}:/home/ -it bamos/openface /bin/bash-v オプションで、コンテナとホスト側でディレクトリを共有できます。
{your dir} は自分の共有したいディレクトリに書き換えてください。
2. ディレクトリの確認
$ cd /root/openface/demos
無事demosディレクトリに入れたら環境構築完了です。
Dockerは便利です!
OpenFaceによる表現獲得
さて、いよいよ画像解析をはじめていきましょう!
顔画像から表現を獲得する方法はいくつかありますが、今回はGoogleが出しているFaceNet:A Unified Embedding for Recognition and Clusteringに記載されている手法を実装した、OpenFaceを使います。
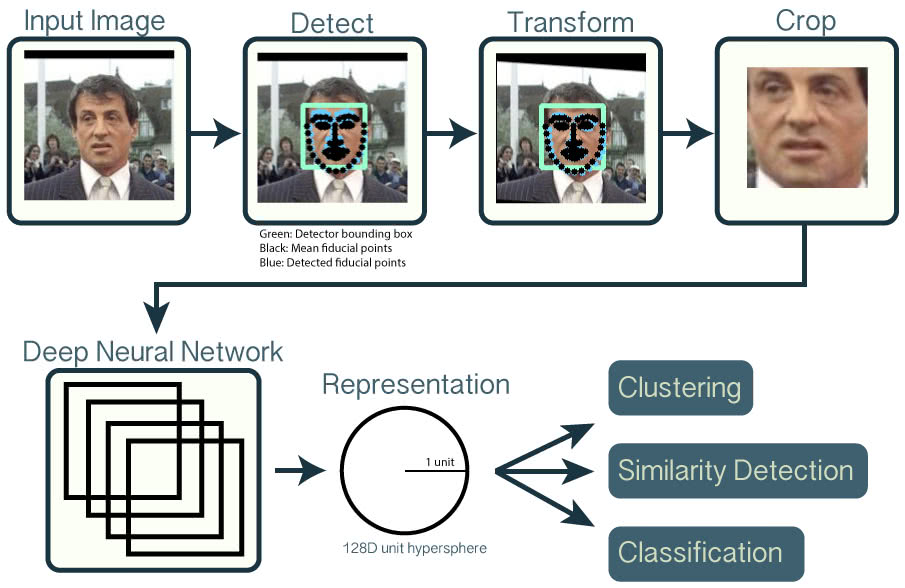
OpenFaceのAPIを利用すると、人の顔画像を128次元ベクトルへ変換し、画像同士のユークリッド距離が直接類似度となるようにマッピングを行ってくれます。
実際に2つの画像を特徴変換し、ユーグリッド距離(類似度)を出してみましょう。
利用する画像は次の2枚です。(Dockerコンテナを立てた際にこの2枚のサンプル画像も入っています)

lennon-1.jpg

carell.jpg
/root/openface/demo/ フォルダに以下のファイルを作成します。
#!/usr/bin/env python2 # -*-coding:utf-8 -*- import cv2 import numpy as np np.set_printoptions(precision=2) import sys import os import openface import glob import itertools fileDir = os.path.dirname(os.path.realpath(__file__)) modelDir = os.path.join(fileDir, '..', 'models') dlibModelDir = os.path.join(modelDir, 'dlib') openfaceModelDir = os.path.join(modelDir, 'openface') class Rep: def __init__(self): # モデル読み込み self.align = openface.AlignDlib(os.path.join(dlibModelDir, "shape_predictor_68_face_landmarks.dat")) self.net = openface.TorchNeuralNet(os.path.join(openfaceModelDir, 'nn4.small2.v1.t7'), 96) def get_rep(self,imgPath): # 画像の読み込み bgrImg = cv2.imread(imgPath) rgbImg = cv2.cvtColor(bgrImg, cv2.COLOR_BGR2RGB) # boundingboxやalign faceなどを作成 bb = self.align.getLargestFaceBoundingBox(rgbImg) alignedFace = self.align.align(96, rgbImg, bb,landmarkIndices=openface.AlignDlib.OUTER_EYES_AND_NOSE) # 128D vectorに変換 rep = self.net.forward(alignedFace) return rep if __name__=="__main__": reps = Rep() img1,img2 = sys.argv[1],sys.argv[2] # get rep array img1_rep, img2_rep = reps.get_rep(img1),reps.get_rep(img2) # 各画像のベクトル表示 #print(img1_rep,img2_rep) # 類似度計算 d = img1_rep - img2_rep print(np.dot(d,d))
実行は以下のコマンドで行います。
$ python compare_images.py /root/openface/images/examples/lennon-1.jpg /root/openface/images/examples/carell.jpg 1.9628270995
この場合は第一引数に lennon-1.jpg 、第二引数に carell.jpg をとり、両者を比較しています。
1.9628270995 という実行結果はユークリッド距離(類似度)で、0に近いほど同一人物ということが言えます。
論文では、類似度の閾値を1.1程度としています。つまり、類似度が1.1以下なら同一人物、
1.1以上なら別人物というわけですね。ただし、光の加減やピクセル数等によって閾値は多少前後します。1.1を基準とし、しっくりくる閾値を見つけてみてください。
本テーマである来店数の多い人(常連さん)を発見するには、画像から取得した表現をユーグリッド空間にプロットし、それをクラスタリングすることで、同一人物のクラスタを作成することを考えます。
参考として、どのようなことをすればよいかを可視化しました。
可視化のために各画像を主成分分析(PCA1)により50次元まで次元削減し、t-sne2によって2次元まで顔画像を落としこみプロットしています。
koike,liさん,yonetaniさんの顔画像を50枚前後用意し、次元削減を行い2次元に無理やり落とし込みました。
(※次元削減しているので、各点間の距離が直接の類似度になるとは限らないので注意)
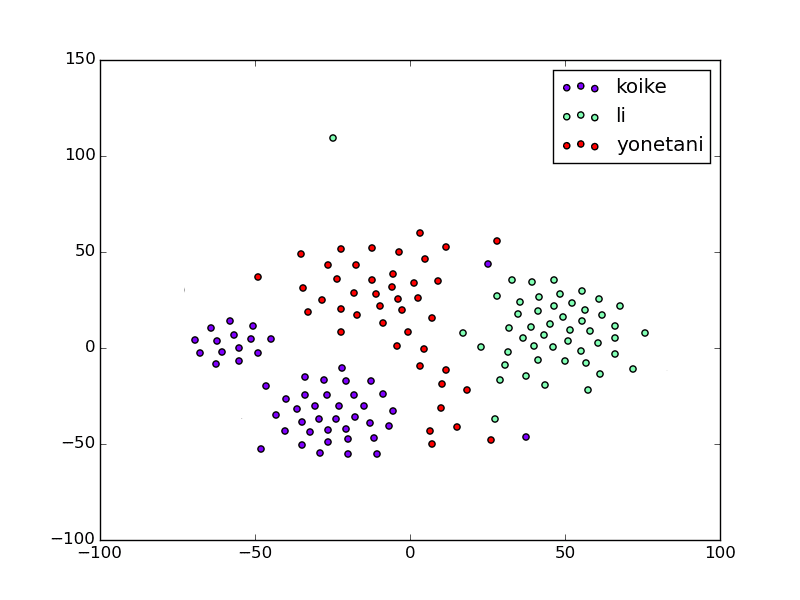
各点は、顔画像を無理やりに2次元に落とし込んだものです。
なんとなくクラスタリングできそうですね!
クラスタリング手法について
では、クラスタリングはどのように行えば良いでしょうか。
今回のクラスタリングは、 クラスタ数が事前にわかりません。
来店するお客さんの例で説明すると、来店した人の顔画像はあるけど、よく来店する人の数(クラスター数)はわからない状況です。
そこで、クラスタリングの中でもクラスタ数を指定しないアプローチをしなければなりません。
クラスター数を指定しないアルゴリズムはMeanShift、DBSCAN、x-meansなどがありますが3、
今回はDBSCANを利用してクラスタリングを行います。
DBSCANによるクラスタリング
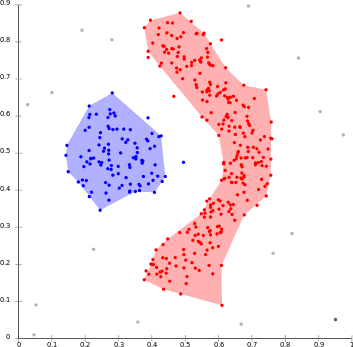
DBSCANの簡単な説明をします。
ある点 (p) から近傍半径 (\xi) 以内に少なくとも (minPts) 数の点があれば、
その点 (p) は (core-points) といいます。また、近傍半径内にある点を到達可能点と言います。
点pの近傍半径 (\xi) 内の点を (core-points) か判断し、(core-points) を移動させながら同じ動作を繰り返します。
各点から到達可能である点は同じクラスタと判断します。
視覚的に表すと以下のようになり、密接な点を同一クラスとみなしてクラスタリングを行っていることがわかります。
(厳密に言うと、条件があったり等少々異なった箇所がありますが、今回はこのような理解で構いません。)
DBSCANは、指定するパラメータは2で良いです。1つは近傍半径 (\xi) 、もう1つは円内に含まれる最低オブジェクト数 (minPts) です。
今回のクラスタリングは、(\xi = 0.7)、(minPts = 1)として行いました。
(ただし、先ほど類似度の所でも述べましたが、被写体の光の具合・撮影距離等によって近傍半径の調整が必要です。クラスタリングを行う場合、まずは少数データで近傍半径を調整した後にクラスタリングすることをおすすめします)
このクラスタリングを行うにはいろいろな人の顔画像を用意する必要があります。
顔画像データセットを /home/ 以下に設置してください。
(ディレクトリを共有しているので、ホスト側の/home/{your dir}に画像データをおいてOKです。)
なお、今回私は以下のように画像を用意しました。
/home/ |-- 0aaa.jpg |-- 0bbb.jpg |-- 0ccc.jpg |-- 0ddd.jpg |-- 10bbb.jpg |-- 10ccc.jpg |-- 11aaa.jpg |-- 11bbb.jpg |-- 11ccc.jpg |-- 12bbb.jpg |-- 8aaa.jpg |-- 8bbb.jpg |-- 8ccc.jpg |-- 9bbb.jpg |-- 9ccc.jpg |-- carell.jpg |-- lennon-1.jpg (以下略)
それぞれの合計枚数は下表のとおりです。
| 名前 | 画像枚数 |
|---|---|
| aaaさん | 10 |
| bbbさん | 17 |
| cccさん | 20 |
| dddさん | 3 |
| carellさん | 1 |
| lenon-1さん | 1 |
この5人の顔画像をランダムに集め、 /home/ に置きました。lenonさん、carellさんは先ほどのサンプル画像をそのまま使用しています。
なお、カメラ撮影の関係でファイル名は index+名前.jpg となっています
(例えば、 0aaa.jpg はaaaさんが映った画像です)
そして以下のpythonファイルを作成し、実行します。
#!/usr/bin/env python2
# -*-coding:utf-8 -*-
import cv2
import numpy as np
np.set_printoptions(precision=2)
import os
import openface
import glob
import itertools
from sklearn.cluster import DBSCAN
fileDir = os.path.dirname(os.path.realpath(__file__))
modelDir = os.path.join(fileDir, '..', 'models')
dlibModelDir = os.path.join(modelDir, 'dlib')
openfaceModelDir = os.path.join(modelDir, 'openface')
class Rep:
def __init__(self):
self.align = openface.AlignDlib(os.path.join(
dlibModelDir, "shape_predictor_68_face_landmarks.dat"))
self.net = openface.TorchNeuralNet(os.path.join(
openfaceModelDir, 'nn4.small2.v1.t7'), 96)
def get_rep(self, imgPath):
bgrImg = cv2.imread(imgPath)
rgbImg = cv2.cvtColor(bgrImg, cv2.COLOR_BGR2RGB)
bb = self.align.getLargestFaceBoundingBox(rgbImg)
alignedFace = self.align.align(
96, rgbImg, bb, landmarkIndices=openface.AlignDlib.OUTER_EYES_AND_NOSE)
rep = self.net.forward(alignedFace)
return rep
def get_all_reps(self, files):
# initialize x
reps = None
for file in files:
if reps is None:
reps = self.get_rep(file)
else:
# 画像に顔がなかった場合の例外処理
try:
reps = np.vstack((reps, self.get_rep(file)))
except:
pass
return reps
if __name__ == "__main__":
getreps = Rep()
# get files
files = glob.glob("/home/*.jpg")
# get Reps
reps = getreps.get_all_reps(files)
print(reps)
EPS = 0.7
MINPTS = 1
# dbscan clustering
dbscan = DBSCAN(eps=EPS, min_samples=MINPTS).fit(reps)
ans = dbscan.fit_predict(reps)
print("class", "img")
for a, f in zip(ans, files):
print(a, f)出力は、(クラスタ番号,画像名) となっています。
('class', 'img')
(0, '/home/0aaa.jpg')
(1, '/home/9bbb.jpg')
(2, '/home/3ccc.jpg')
(2, '/home/17ccc.jpg')
(2, '/home/11ccc.jpg')
(3, '/home/lennon-1.jpg')
(0, '/home/17aaa.jpg')
(1, '/home/3bbb.jpg')
(2, '/home/18ccc.jpg')
(2, '/home/2ccc.jpg')
(0, '/home/19aaa.jpg')
(1, '/home/18bbb.jpg')
(1, '/home/13bbb.jpg')
(2, '/home/15ccc.jpg')
(1, '/home/11bbb.jpg')
(1, '/home/15bbb.jpg')
(4, '/home/1ddd.jpg')
(2, '/home/13ccc.jpg')
(1, '/home/5bbb.jpg')
(1, '/home/12bbb.jpg')
(2, '/home/9ccc.jpg')
(2, '/home/0ccc.jpg')
(2, '/home/14ccc.jpg')
(1, '/home/0bbb.jpg')
(2, '/home/16ccc.jpg')
(2, '/home/6ccc.jpg')
(2, '/home/7ccc.jpg')
(0, '/home/6aaa.jpg')
(2, '/home/1ccc.jpg')
(5, '/home/carell.jpg')
(1, '/home/10bbb.jpg')
(0, '/home/13aaa.jpg')
(4, '/home/2ddd.jpg')
(2, '/home/4ccc.jpg')
(0, '/home/15aaa.jpg')
(6, '/home/19bbb.jpg')
(0, '/home/8aaa.jpg')
(2, '/home/10ccc.jpg')
(1, '/home/14bbb.jpg')
(1, '/home/16bbb.jpg')
(0, '/home/11aaa.jpg')
(2, '/home/8ccc.jpg')
(2, '/home/12ccc.jpg')
(0, '/home/14aaa.jpg')
(2, '/home/5ccc.jpg')
(4, '/home/0ddd.jpg')
(1, '/home/1bbb.jpg')
(1, '/home/6bbb.jpg')
(1, '/home/8bbb.jpg')
(1, '/home/17bbb.jpg')
(2, '/home/19ccc.jpg')
(0, '/home/16aaa.jpg')出力を確認すると、aaaさんはクラスタ0、bbbさんはクラスタ1、cccさんはクラスタ2、dddさんはクラスタ4、lennon-1さんはクラスタ3、carellさんはクラスタ5にうまく分類されていることがわかります。
この結果から、常連さんをSVMまたはCNNで学習させモデルを作成することで、次回から常連さんをその場で判別させることができると思います。
最後に
今回は複数枚ある顔画像からよく頻出する人をクラスタリングし、常連(よく出現する人)さんを機械的に抽出できることを具体的なコードを追いながら実践しました。
この技術の応用方法は多くあり、さまざまビジネスへつなげることができると考えています。
フューチャーアーキテクトのデータ分析チームでは、技術的視点だけでなく、ビジネス視点からも応用先を考え技術検証を行っています。
これからもどんどん面白そうな記事を書いていきますので、よろしくお願いします。
投稿日:May 25th 2017